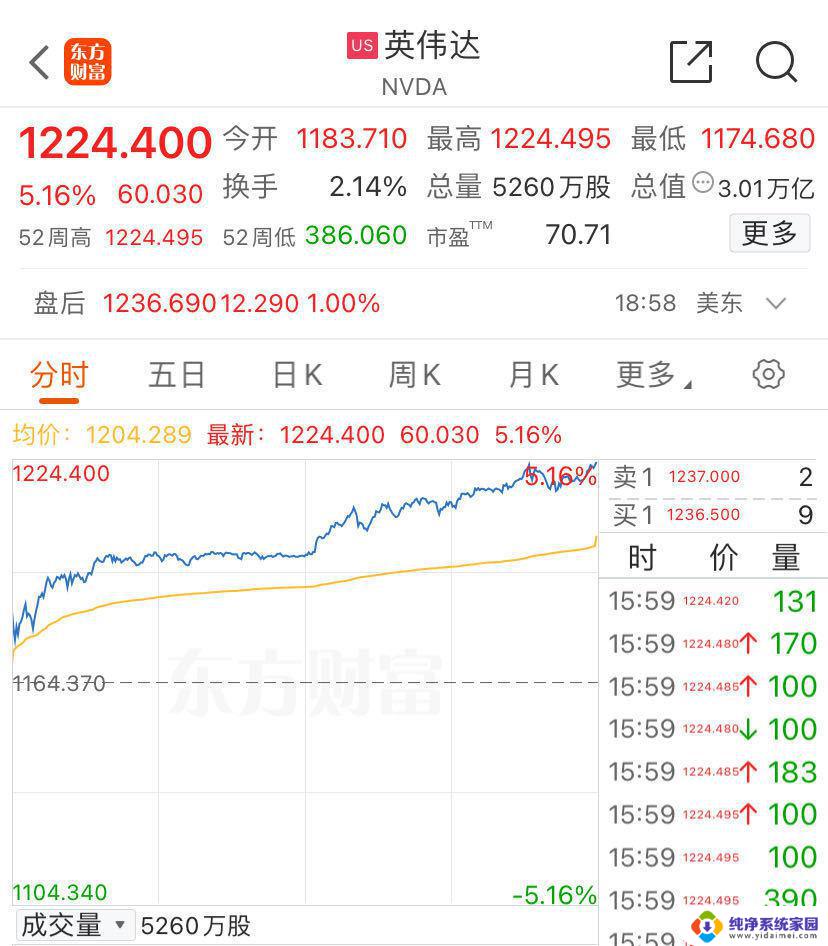
英伟达再破世界纪录,全球最快Llama 4诞生,每秒1000 token!
 来源:机器学习研究组订阅
来源:机器学习研究组订阅你以为,AI推理的速度已经够快了?
不,英伟达还能再次颠覆你的想象——就在刚刚,他们用Blackwell创下了AI推理的新纪录。

仅仅采用单节点(8颗Blackwell GPU)的DGX B200服务器,英伟达就实现了Llama 4 Maverick模型每秒单用户生成1000个token(TPS/user)的惊人成绩!
单节点使用8块B200 GPU
这项速度记录,由AI基准测试服务Artificial Analysis独立测量。
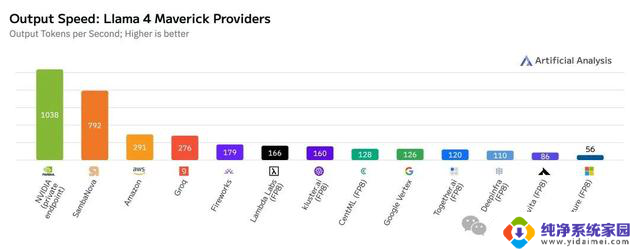
而且,更令人咋舌的是,单台服务器(GB200 NVL72,配备72颗Blackwell GPU)的整体吞吐量,已经达到了72,000 TPS!

GB200 NVL72液冷机架原型机
这场速度革命的幕后,是一整套精心布局的技术组合拳——
使用TensorRT-LLM优化框架和EAGLE-3架构训练推测解码草稿模型;
在GEMM、MoE及Attention计算中全面应用FP8数据格式,有效缩小模型体积并提高计算效率;
应用CUDA内核优化技术(如空间分区、GEMM权重重排、Attention内核并行优化、程序化依赖启动(PDL)等);
运算融合(如FC13+SwiGLU、FC_QKV+attn_scaling、AllReduce+RMSnorm融合)。
由此,Blackwell的性能潜力彻底被点燃,一举实现了4倍加速,直接把之前的最强Blackwell基线甩在身后!
 迄今测试过最快Maverick实现
迄今测试过最快Maverick实现这次优化措施在保持响应准确度的同时,显著提升了模型性能。
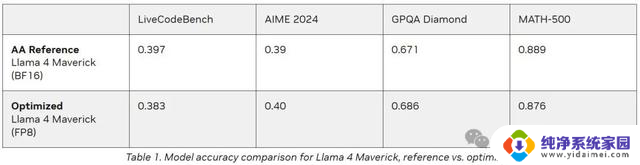
英伟达针对GEMM(通用矩阵乘法)、MoE(混合专家模型)及Attention(注意力)运算运用了FP8数据类型,旨在减小模型体积。并充分利用Blackwell Tensor Core技术所带来的高FP8吞吐量优势。
如下表所示,采用FP8数据格式后。模型在多项评估指标上的准确度可与Artificial Analysis采用BF16数据格式(进行测试)所达到的准确度相媲美:

大部分用生成式AI的场景,都要在吞吐量(throughput)和延迟(latency)之间找一个平衡点,好让很多用户同时使用时,都能有个「还不错」的体验。
但是,有些关键场景,比如要迅速做出重要决策的时候,「响应速度」就变得特别重要,哪怕一点延迟都可能带来严重后果。
无论你想要的是同时处理尽可能多的请求,还是希望既能处理很多请求、响应又比较快,还是只想最快地服务单个用户(即最小化单个用户的延迟),Blackwell的硬件都是最佳选择。
下图概述了英伟达在推理过程中应用的内核优化和融合(以红色虚线框标示)。
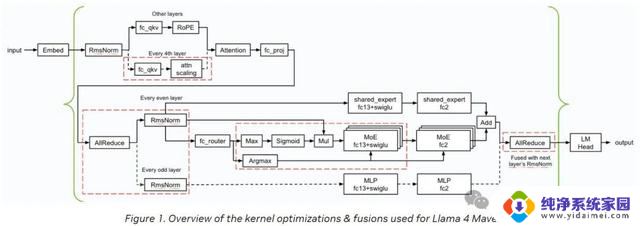
英伟达实现了若干低延迟GEMM内核,并应用了各种内核融合(如FC13+SwiGLU、FC_QKV+attn_scaling以及A